-
추천시스템 예제코드(ML&DL) 프로젝트/머신러닝 App 탑재 2022. 3. 22. 14:29
추천 시스템 (Recommender Systems)
추천 시스템은 크게 두가지로 구분 가능
1. 컨텐츠 기반 필터링 (content-based filtering)
- 컨텐츠 기반 필터링은 지금까지 사용자의 이전 행동과 명시적 피드백을 통해 사용자가 좋아하는 것과 유사한 항목을 추천
2. 협업 필터링 (collaborative filtering)
- 협업 필터링은 사용자와 항목간의 유사성을 동시에 사용해 추천
3. 두가지를 조합한 하이브리드 방식도 가능
< 실습 코드 >
1. 실습 준비

Surprise
- 추천 시스템 전용 라이브러리
- 다양한 모델과 데이터 제공
- scikit-learn과 유사한 사용 방법

surprise 모듈 불러온 후에, 데이터셋을 불러오고 raw_ratings를 사용해서
rating값 10개만 추려서 출력한다. 어떤 사용자가 어떤 영화에 대해서 어떻게 rating을 했느냐를 파악해야 한다.
데이터 구조를 살펴보면,
맨 왼쪽부터 순서대로 유저, 아이템(영화), 점수(평점), ID 이다.
모델에 간단하게 적용시켜 테스팅을 해보면 다음과 같다.
Model : SVD ( Singulat value decomposition)
영화 평점이라는 행렬(A)을 SVD를 이용하여 사용자 행렬(U), 특성 행렬(Σ), 영화 행렬(Vt)
)로 만들어서 추천 데이터 생성에 필요한 데이터를 최소화 하고, 비어있는 고객의 평점을 예측하여 추천 시스템에 적용하는 방법을 설명 합니다.

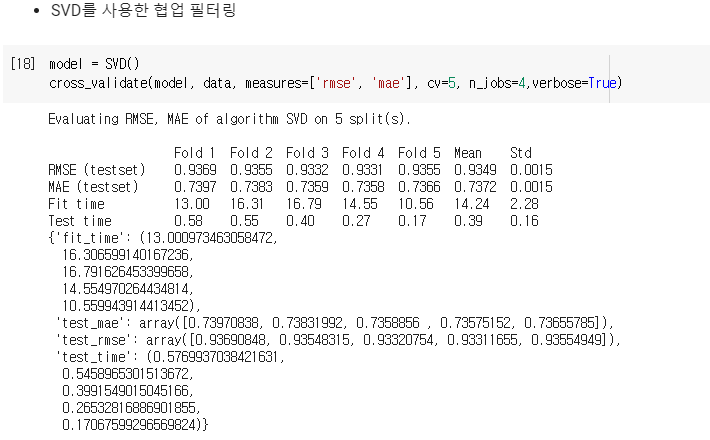
각각의 measure를 SVD를 통해서 검증해본다.

Folding 5개를 보니까 RMSE, MAE 각각의 성능이 나왔다.
fit_time은 대략 5초 정도가 나왔다.
2. 컨텐츠 기반 필터링
이전의 행동과 명시적인 피드백을 통해서 좋아하는 것과 유사한 항목을 추천하는 것
ex) 내가 지금까지 시청했던 영화 목록과 다른 사용자의 시청 목록을 비교하여 비슷한 취향의 사용자가 시청한 영화를 추천
유사도 기반으로 추천, 아래와 같은 장단점이 있음
장점
1. 많은 수의 사용자를 대상으로 쉽게 확장 가능
2. 사용자가 관심 갖지 않던 상품 추천 가능
단점
1. 입력 특성을 직접 설계해야 하기 때문에 도메인 지식이 많이 필요
2. 사용자의 기존 관심사항을 기반으로 추천해야 함 (예외 케이스를 잘 살펴야 함)

shape 행렬에 대한 인접 행렬을 만들어 보자.

어떤 특정 위치, [user_id][movie_id] 에 1을 넣어준다.
1이 있는 위치가 데이터가 있는 위치임을 확인
(1) 유사도 기반으로 찾아보기
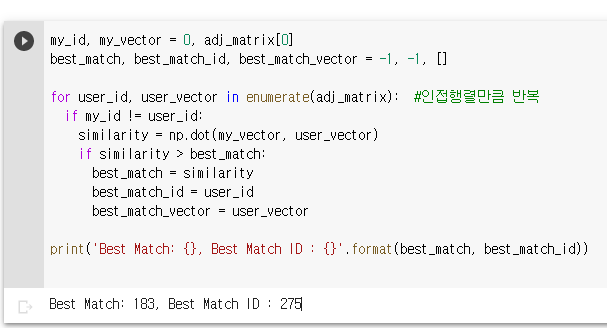
만약 user_id와 내가 다르다면, similarity 계산을 해준다.
만약 유사성이 best_match보다 값이 크다면, best_match를 similarity로 바꿔준다.
그리고 user_id가 best_match_id / user_vector가 best_match_vector로 바뀐다.
결과적으로, print 해보면 0번째 id와 나 자신이 아닌 id를 비교해본 결과
183의 결과가 나오고 best match id가 275로 나오게 된다.
따라서, 유사도 검사에 따라서 return을 시키게 된다.
recommend list 뽑기 (유사도)

(2) 유클리디언을 통해서 찾아보기

recommend 리스트 뽑기 (유클리디언)

(3) 코사인 유사도를 통해서 찾아보기

+) 기존 방법에 사용자가 rating한 값을 활용해보기
이전은 봤는지 아닌지 (1,0)을 넣었다면, 지금은 rating 한 값을 넣어서 테스트한다.


3. 협업 필터링 (Collaborative Filtering)
- 사용자와 항목의 유사성을 동시에 고려해서 추천
- 기존에 내 관심사가 아닌 항목이라도 추천이 가능하다.
- 학습 과정에서 나오지 않은 항목은 임베딩이 어렵고, 추가 특성을 사용하기 어렵다.


3. 하이브리드(Hybrid)
- 컨텐츠 기반 필터링과 협업 필터링을 조합한 방식
- 많은 하이브리드 방식이 존재
- 실습에서는 협업 필터링으로 임베딩을 학습하고 컨텐츠 기반 필터링으로 유사도 기반 추천을 수행하는 추천 엔진 개발


U와 V 사이의 S 행렬이 있는데, 잠재적인 특이값 벡터라고 이해할 수 있다.

다시 복원된 행렬의 모습
(1) 사용자 기반 추천
나와 비슷한 취향을 가진 다른 사용자의 행동을 추천
사용자 특징 벡터의 유사도 사용

이렇게 하이브리드 방식대로 SVD를 돌리고 컨텐츠기반의 코사인유사도를 적용해서 확인해본 결과,
0.99의 성능이 나오는 것을 확인할 수 있다.

추천 리스트 뽑아서 확인
(2)항목 기반 추천
내가 본 항목과 비슷한 항목을 추천
항목 특징 벡터의 유사도 사용


'(ML&DL) 프로젝트 > 머신러닝 App 탑재' 카테고리의 다른 글
추천시스템 알고리즘 선정 (0) 2022.06.19 tensorflow.js 관련 서적 (0) 2022.04.03 Tensorflow.lite / Tensorflow.js / CoreML (0) 2022.03.23